Tiger Cloud: Performance, Scale, Enterprise, Free
Self-hosted products
MST
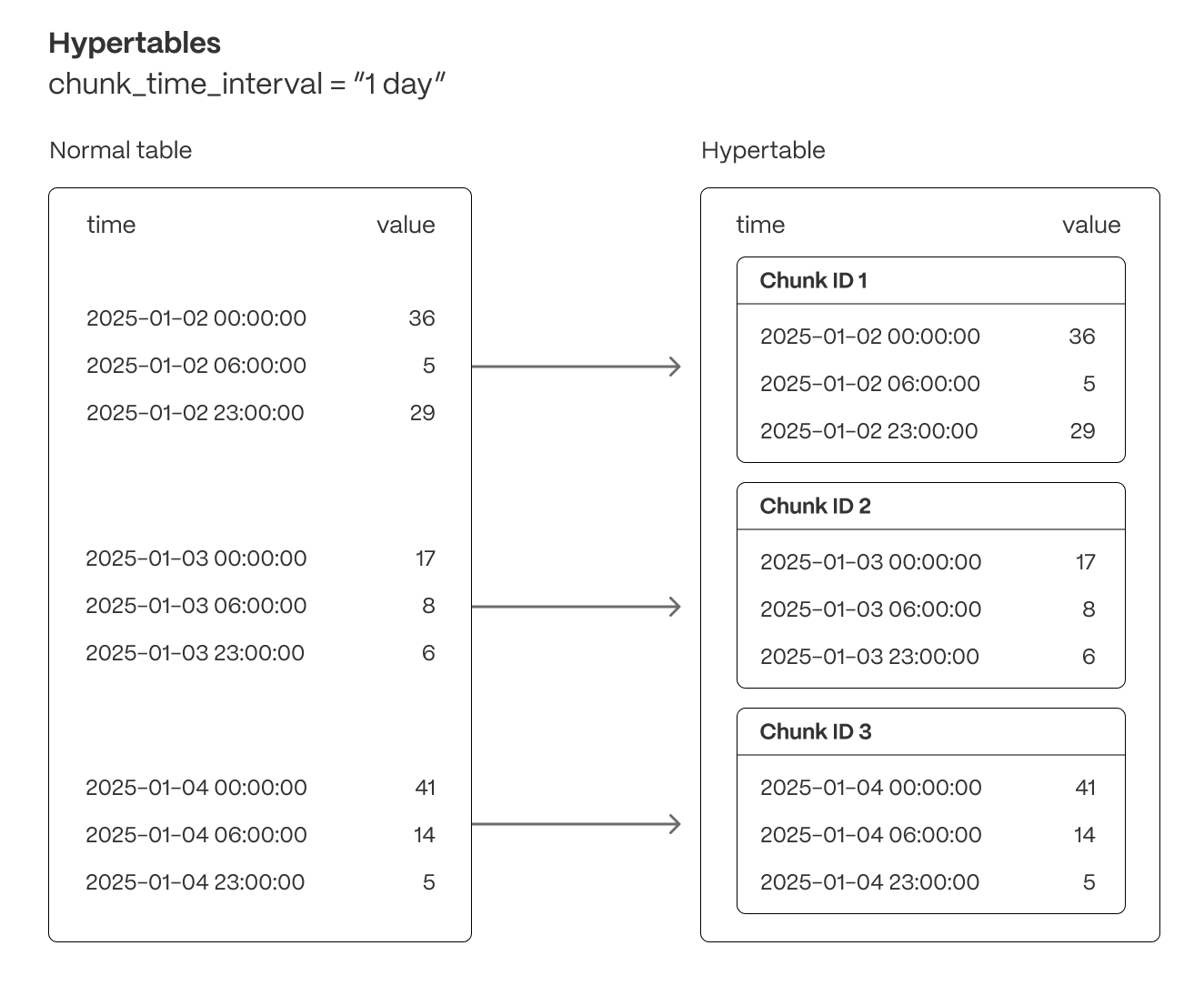
Tiger Cloud supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables—Postgres tables that automatically partition your time-series data by time and optionally by other dimensions. When you run a query, Tiger Cloud identifies the correct partition, called chunk, and runs the query on it, instead of going through the entire table.
Hypertables offer the following benefits:
Efficient data management with automated partitioning by time: Tiger Cloud splits your data into chunks that hold data from a specific time range. For example, one day or one week. You can configure this range to better suit your needs.
Better performance with strategic indexing: an index on time in the descending order is automatically created when you create a hypertable. More indexes are created on the chunk level, to optimize performance. You can create additional indexes, including unique indexes, on the columns you need.
Faster queries with chunk skipping: Tiger Cloud skips the chunks that are irrelevant in the context of your query, dramatically reducing the time and resources needed to fetch results. Even more—you can enable chunk skipping on non-partitioning columns.
Advanced data analysis with hyperfunctions: Tiger Cloud enables you to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
To top it all, there is no added complexity—you interact with hypertables in the same way as you would with regular Postgres tables. All the optimization magic happens behind the scenes.

Note
Inheritance is not supported for hypertables and may lead to unexpected behavior.
For more information about using hypertables, including chunk size partitioning, see the hypertable section.
Best practice for using a hypertable is to:
Create a hypertable
Create a hypertable for your time-series data using CREATE TABLE. For efficient queries on data in the columnstore, remember to
segmentbythe column you will use most often to filter your data. For example:CREATE TABLE conditions (time TIMESTAMPTZ NOT NULL,location TEXT NOT NULL,device TEXT NOT NULL,temperature DOUBLE PRECISION NULL,humidity DOUBLE PRECISION NULL) WITH (tsdb.hypertable,tsdb.partition_column='time',tsdb.segmentby = 'device',tsdb.orderby = 'time DESC');If you are self-hosting TimescaleDB v2.19.3 and below, create a Postgres relational table
 ,
then convert it using create_hypertable. You then enable hypercore with a call
to ALTER TABLE.
,
then convert it using create_hypertable. You then enable hypercore with a call
to ALTER TABLE.Set the columnstore policy
CALL add_columnstore_policy('conditions', after => INTERVAL '1d');
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.