Tiger Cloud: Performance, Scale, Enterprise
Self-hosted products
MST
You use the source S3 connector in Tiger Cloud to synchronize CSV and Parquet files from an S3 bucket to your Tiger Cloud service in real time. The connector runs continuously, enabling you to leverage Tiger Cloud as your analytics database with data constantly synced from S3. This lets you take full advantage of Tiger Cloud's real-time analytics capabilities without having to develop or manage custom ETL solutions between S3 and Tiger Cloud.
You can use the source S3 connector to synchronize your existing and new data. Here's what the connector can do:
Sync data from an S3 bucket instance to a Tiger Cloud service:
- Use glob patterns to identify the objects to sync.
- Watch an S3 bucket for new files and import them automatically. It runs on a configurable schedule and tracks processed files.
- Important: The connector processes files in lexicographical order
 . It uses the name of the last file processed as a marker and fetches only files later in the alphabet in subsequent queries. Files added with names earlier in the alphabet than the marker are skipped and never synced. For example, if you add the file Bob when the marker is at Elephant, Bob is never processed.
. It uses the name of the last file processed as a marker and fetches only files later in the alphabet in subsequent queries. Files added with names earlier in the alphabet than the marker are skipped and never synced. For example, if you add the file Bob when the marker is at Elephant, Bob is never processed. - For large backlogs, check every minute until caught up.
Sync data from multiple file formats:
- CSV: check for compression in GZ and ZIP format, then process using timescaledb-parallel-copy.
- Parquet: convert to CSV, then process using timescaledb-parallel-copy.
- CSV: check for compression in GZ and ZIP format, then process using timescaledb-parallel-copy
The source S3 connector offers an option to enable a hypertable during the file-to-table schema mapping setup. You can enable columnstore and continuous aggregates through the SQL editor once the connector has started running.
The connector offers a default 1-minute polling interval. This means that Tiger Cloud checks the S3 source every minute for new data. You can customize this interval by setting up a cron expression.
The source S3 connector continuously imports data from an Amazon S3 bucket into your database. It monitors your S3 bucket for new files matching a specified pattern and automatically imports them into your designated database table.
Note: the connector currently only syncs existing and new files—it does not support updating or deleting records based on updates and deletes from S3 to tables in a Tiger Cloud service.
Early access: this source S3 connector is not supported for production use. If you have any questions or feedback, talk to us in #livesync in the Tiger CommunityTo follow the steps on this page:
Create a target Tiger Cloud service with real-time analytics enabled.
You need your connection details.
Ensure access to a standard Amazon S3 bucket containing your data files.
Directory buckets are not supported.
Configure access credentials for the S3 bucket.
The following credentials are supported:Configure the trust policy. Set the:
Principal:arn:aws:iam::142548018081:role/timescale-s3-connections.ExternalID: set to the Tiger Cloud project and Tiger Cloud service ID of the service you are syncing to in the format<projectId>/<serviceId>.This is to avoid the confused deputy problem
.
Give the following access permissions:
s3:GetObject.s3:ListBucket.

Note
This feature is currently not supported for Tiger Cloud on Microsoft Azure.
File naming: Files must follow lexicographical ordering conventions. Files with names that sort earlier than already-processed files are permanently skipped. Example: if
file_2024_01_15.csvhas been processed, a file namedfile_2024_01_10.csvadded later will never be synced. Recommended naming patterns: timestamps (for example,YYYY-MM-DD-HHMMSS), sequential numbers with fixed padding (for example,file_00001,file_00002).CSV:
Maximum file size: 1 GB
To increase this limit, contact sales@tigerdata.com
Maximum row size: 2 MB
Supported compressed formats:
- GZ
- ZIP
Advanced settings:
- Delimiter: the default character is
,, you can choose a different delimiter - Skip header: skip the first row if your file has headers
- Delimiter: the default character is
Parquet:
- Maximum file size: 1 GB
- Maximum row size: 2 MB
Sync iteration:
To prevent system overload, the connector tracks up to 100 files for each sync iteration. Additional checks only fill empty queue slots.
To sync data from your S3 bucket to your Tiger Cloud service using Tiger Cloud Console:
Connect to your Tiger Cloud service
In Tiger Cloud Console
, select the service to sync live data to.Connect the source S3 bucket to the target service
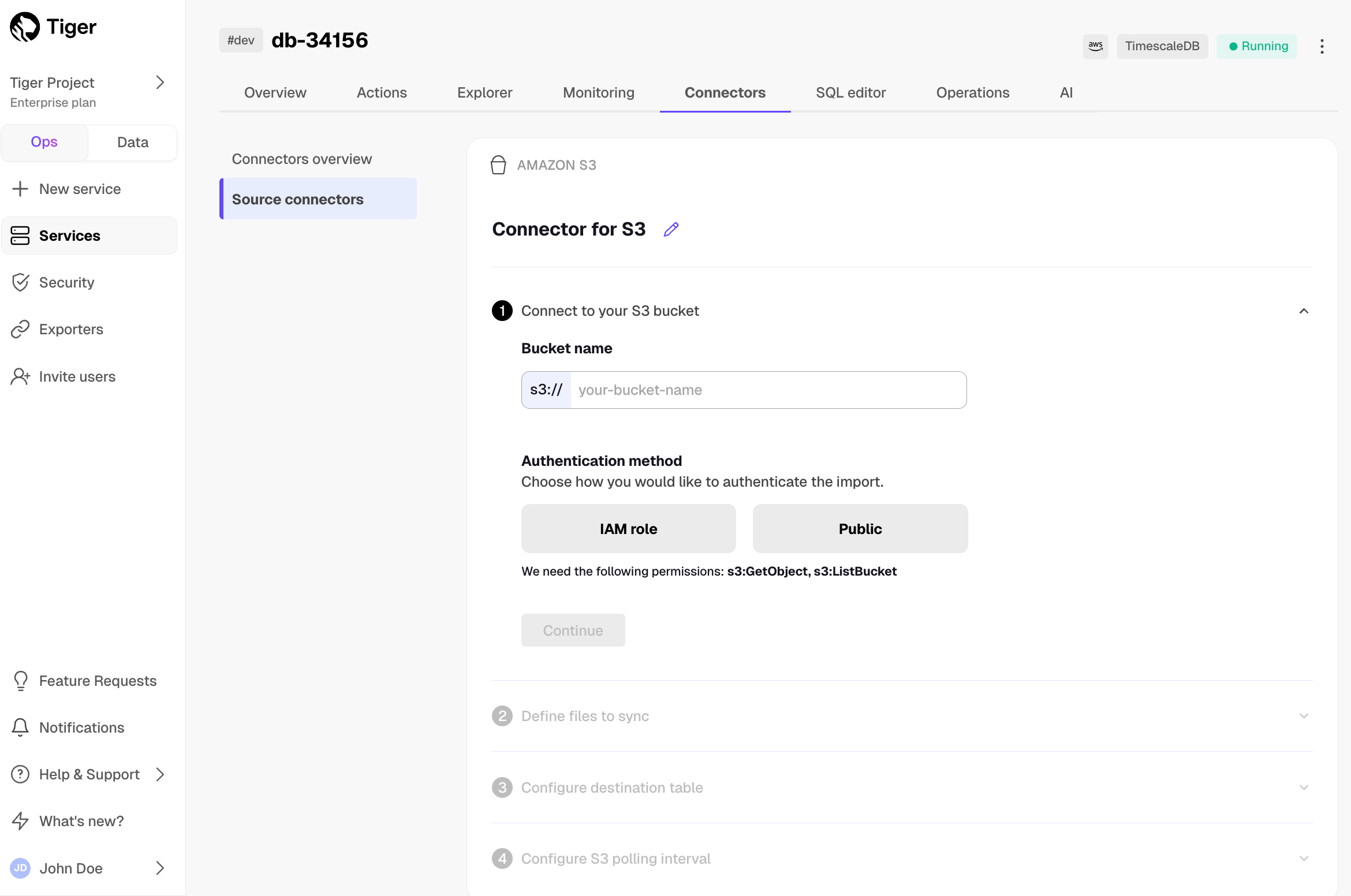
Click
Connectors>Amazon S3.Click the pencil icon, then set the name for the new connector.
Set the
Bucket nameandAuthentication method, then clickContinue.For instruction on creating the IAM role to connect your S3 bucket, click
Learn how. Tiger Cloud Console connects to the source bucket.In
Define files to sync, choose theFile typeand set theGlob pattern.Use the following patterns:
<folder name>/*: match all files in a folder. Also, any pattern ending with/is treated as/*.<folder name>/**: match all recursively.<folder name>/**/*.csv: match a specific file type.
The source S3 connector uses prefix filters where possible, place patterns carefully at the end of your glob expression. AWS S3 doesn't support complex filtering. If your expression filters too many files, the list operation may time out.
Click the search icon. You see the files to sync. Click
Continue.
Optimize the data to synchronize in hypertables
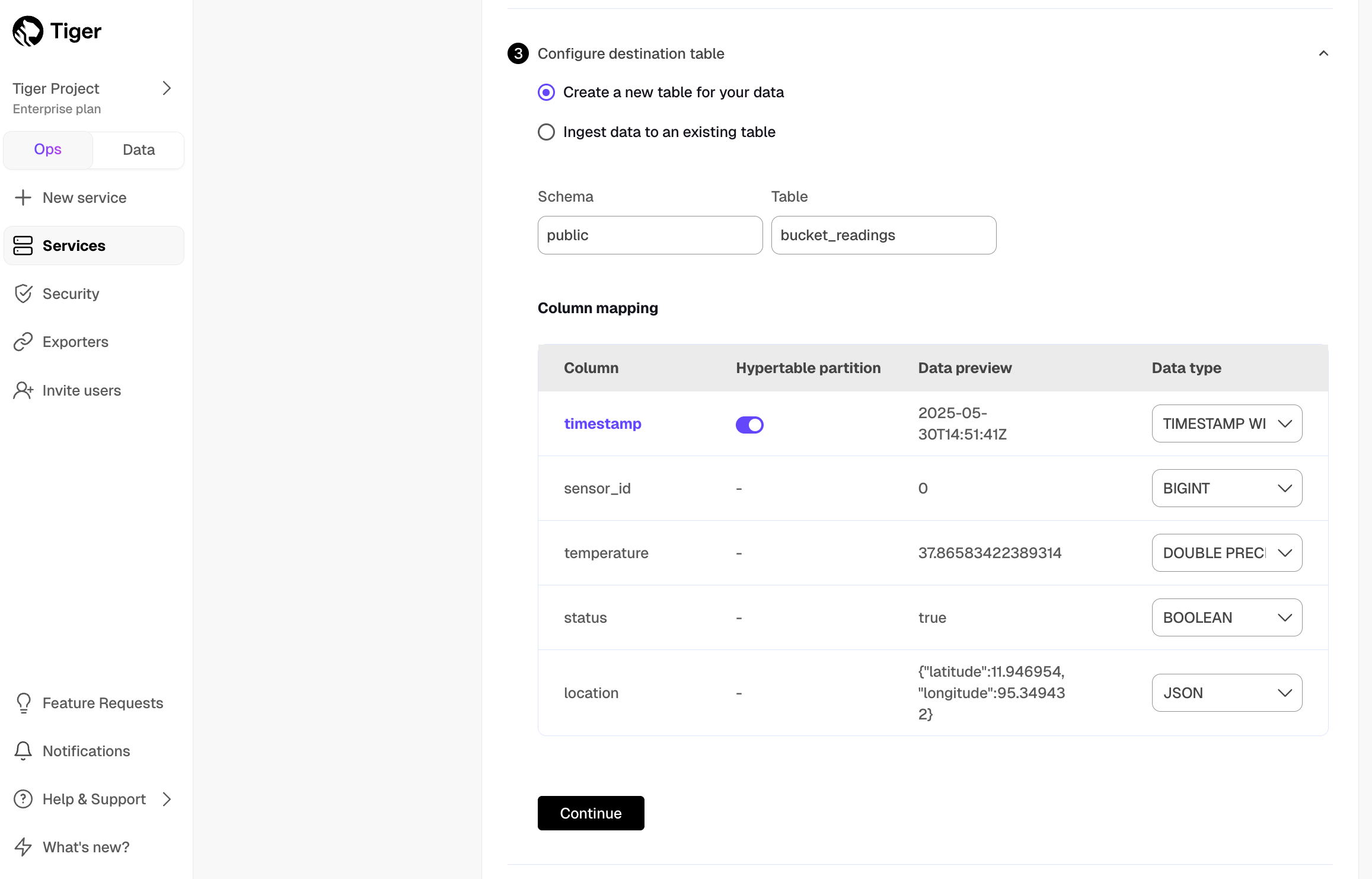
Tiger Cloud Console checks the file schema and, if possible, suggests the column to use as the time dimension in a hypertable.
Choose
Create a new table for your dataorIngest data to an existing table.Choose the
Data typefor each column, then clickContinue.Choose the interval. This can be a minute, an hour, or use a cron expression
.Click
Start Connector.Tiger Cloud Console starts the connection between the source database and the target service and displays the progress.
Monitor synchronization
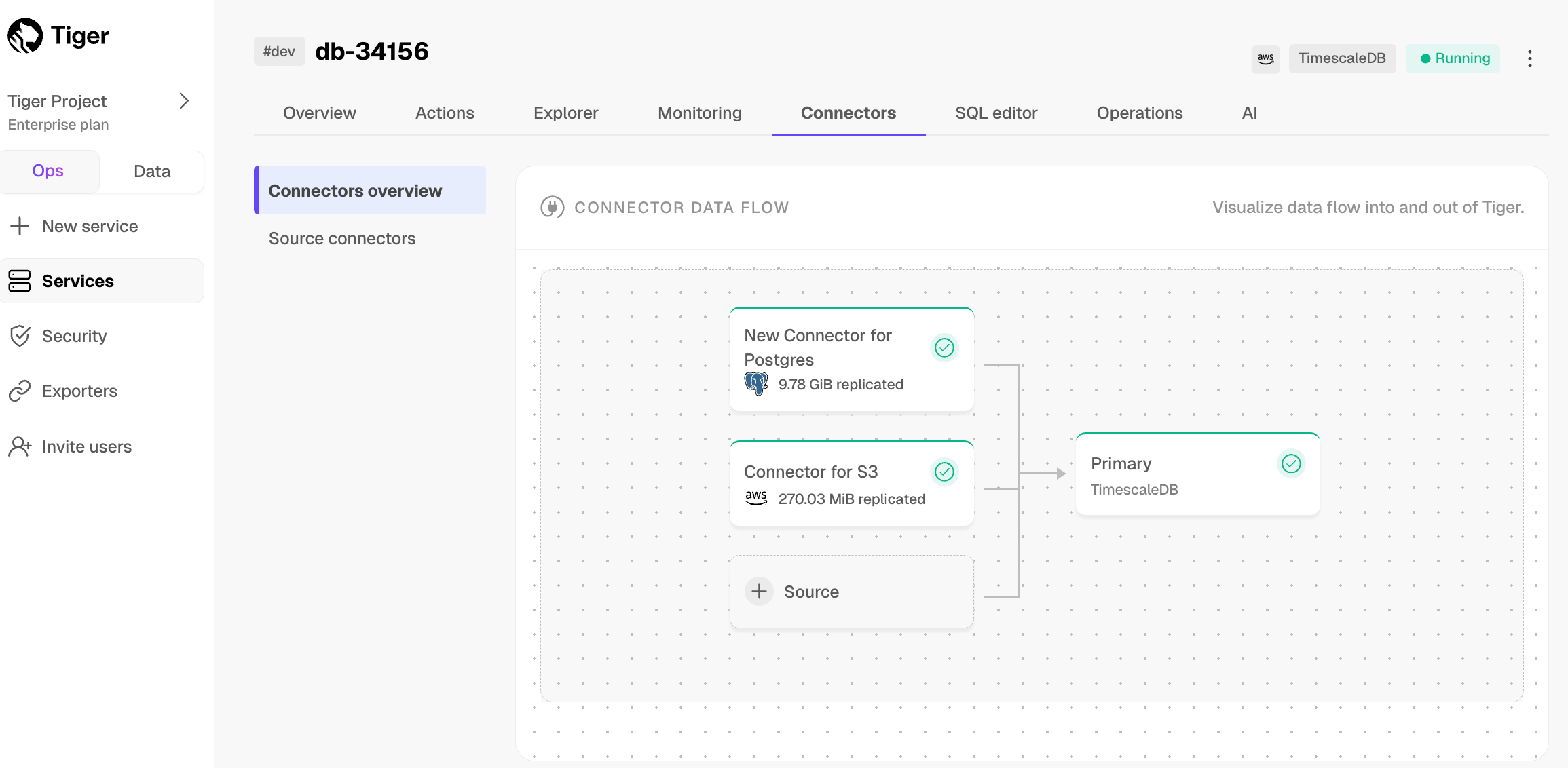
To view the amount of data replicated, click
Connectors. The diagram inConnector data flowgives you an overview of the connectors you have created, their status, and how much data has been replicated.To view file import statistics and logs, click
Connectors>Source connectors, then select the name of your connector in the table.
Manage the connector
To pause the connector, click
Connectors>Source connectors. Open the three-dot menu next to your connector in the table, then clickPause.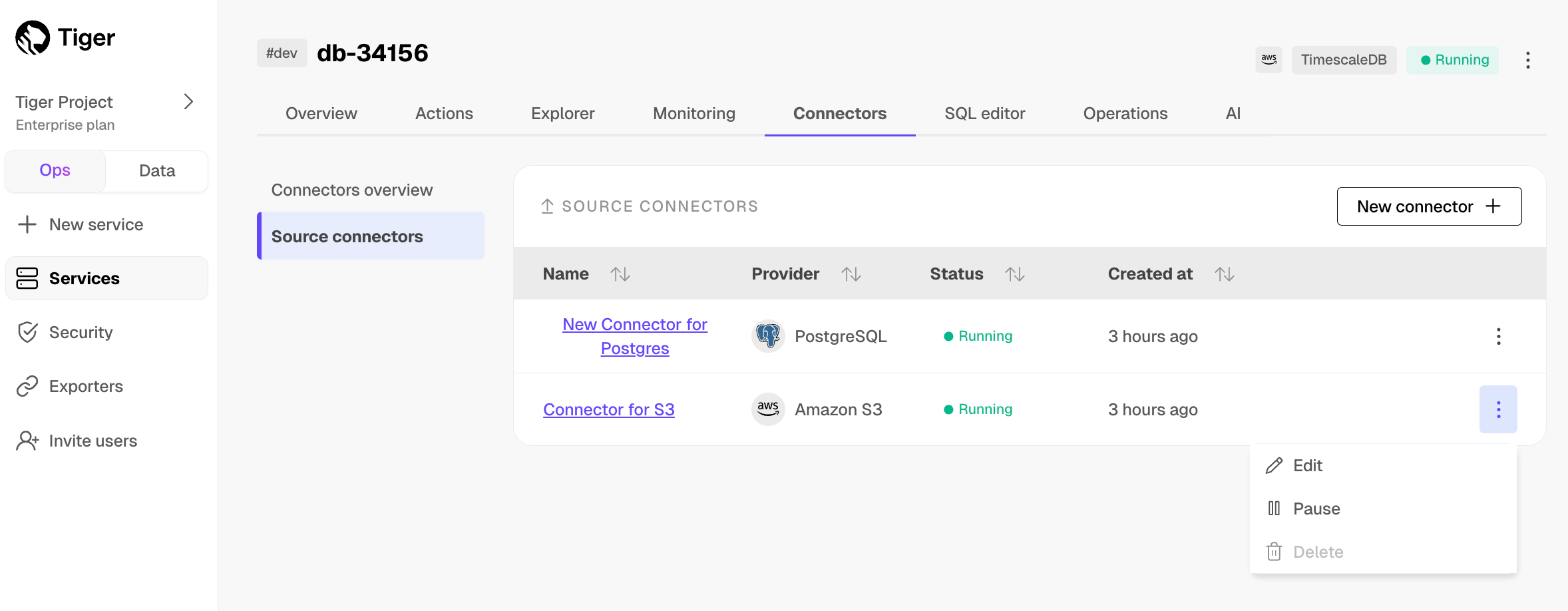
To edit the connector, click
Connectors>Source connectors. Open the three-dot menu next to your connector in the table, then clickEditand scroll down toModify your Connector. You must pause the connector before editing it.
To pause or delete the connector, click
Connectors>Source connectors, then open the three-dot menu on the right and select an option. You must pause the connector before deleting it.
And that is it, you are using the source S3 connector to synchronize all the data, or specific files, from an S3 bucket to your Tiger Cloud service in real time.
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.