Tiger Cloud: Performance, Scale, Enterprise, Free
Self-hosted products
MST
Tiger Cloud supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables—Postgres tables that automatically partition your time-series data by time and optionally by other dimensions. When you run a query, Tiger Cloud identifies the correct partition, called chunk, and runs the query on it, instead of going through the entire table.
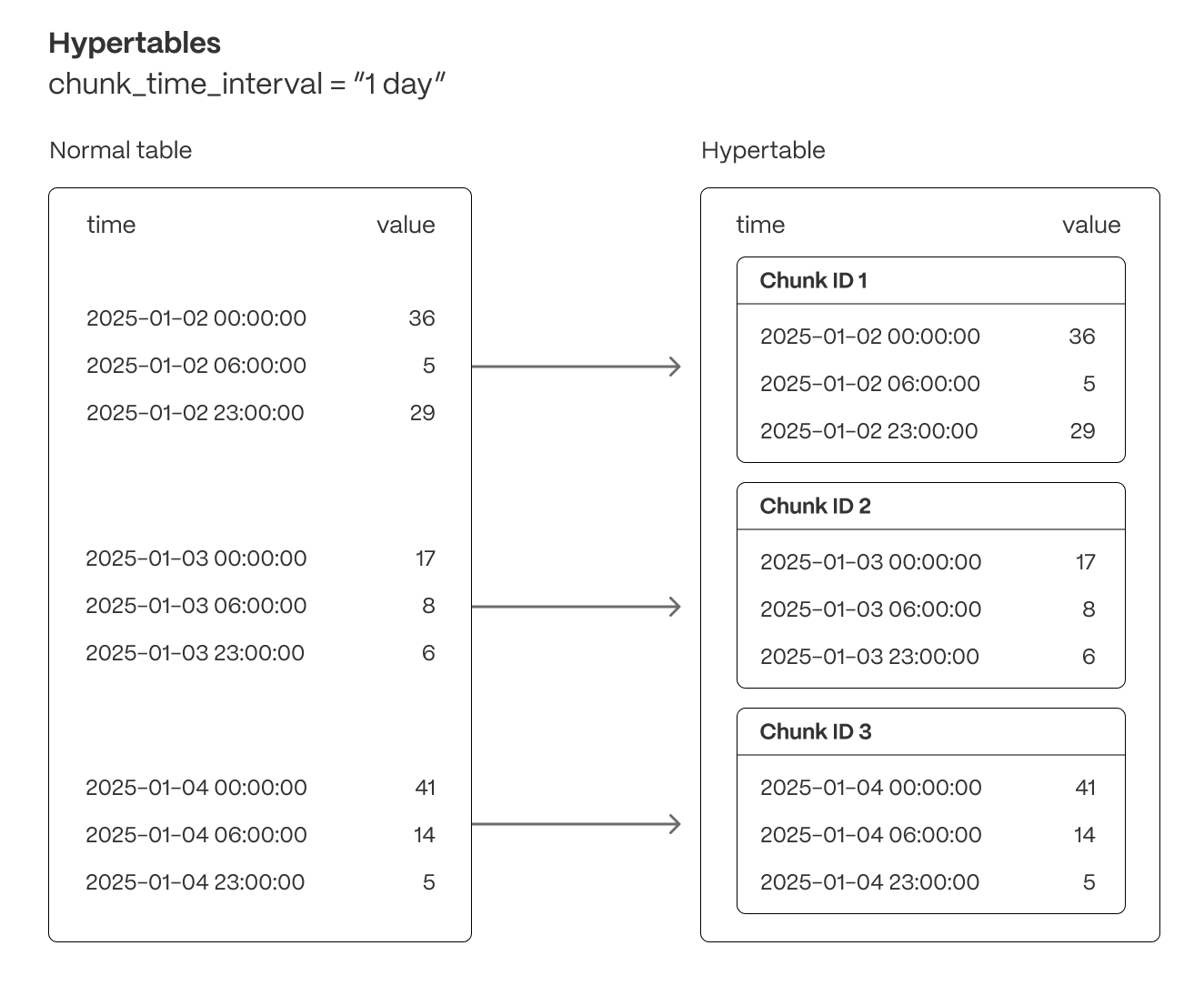
Hypertables offer the following benefits:
Efficient data management with automated partitioning by time: Tiger Cloud splits your data into chunks that hold data from a specific time range. For example, one day or one week. You can configure this range to better suit your needs.
Better performance with strategic indexing: an index on time in the descending order is automatically created when you create a hypertable. More indexes are created on the chunk level, to optimize performance. You can create additional indexes, including unique indexes, on the columns you need.
Faster queries with chunk skipping: Tiger Cloud skips the chunks that are irrelevant in the context of your query, dramatically reducing the time and resources needed to fetch results. Even more—you can enable chunk skipping on non-partitioning columns.
Advanced data analysis with hyperfunctions: Tiger Cloud enables you to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
To top it all, there is no added complexity—you interact with hypertables in the same way as you would with regular Postgres tables. All the optimization magic happens behind the scenes.

Note
Inheritance is not supported for hypertables and may lead to unexpected behavior.
Each hypertable is partitioned into child hypertables called chunks. Each chunk is assigned a range of time, and only contains data from that range.
Typically, you partition hypertables on columns that hold time values.
Best practice is to use timestamptz![]() column type. However, you can also partition on
column type. However, you can also partition on
date, integer, timestamp and UUIDv7 types.
By default, each hypertable chunk holds data for 7 days. You can change this to better suit your
needs. For example, if you set chunk_interval to 1 day, each chunk stores data for a single day.
TimescaleDB divides time into potential chunk ranges, based on the chunk_interval. Each hypertable chunk holds
data for a specific time range only. When you insert data from a time range that doesn't yet have a chunk, TimescaleDB
automatically creates a chunk to store it.
In practice, this means that the start time of your earliest chunk does not necessarily equal the earliest timestamp in your hypertable. Instead, there might be a time gap between the start time and the earliest timestamp. This doesn't affect your usual interactions with your hypertable, but might affect the number of chunks you see when inspecting it.
Best practices for maintaining a high performance when scaling include:
- Limit the number of hypertables in your service; having tens of thousands of hypertables is not recommended.
- Choose a strategic chunk size.
Chunk size affects insert and query performance. You want a chunk small enough to fit into memory so you can insert and query recent data without reading from disk. However, having too many small and sparsely filled chunks can affect query planning time and compression. The more chunks in the system, the slower that process becomes, even more so when all those chunks are part of a single hypertable.
Postgres builds the index on the fly during ingestion. That means that to build a new entry on the index, a significant portion of the index needs to be traversed during every row insertion. When the index does not fit into memory, it is constantly flushed to disk and read back. This wastes IO resources which would otherwise be used for writing the heap/WAL data to disk.
The default chunk interval is 7 days. However, best practice is to set chunk_interval so that prior to processing,
the indexes for chunks currently being ingested into fit within 25% of main memory. For example, on a system with 64
GB of memory, if index growth is approximately 2 GB per day, a 1-week chunk interval is appropriate. If index growth is
around 10 GB per day, use a 1-day interval.
You set chunk_interval when you create a hypertable, or by calling
set_chunk_time_interval on an existing hypertable.
For a detailed analysis of how to optimize your chunk sizes, see the
blog post on chunk time intervals![]() . To learn how
to view and set your chunk time intervals, see
Optimize hypertable chunk intervals.
. To learn how
to view and set your chunk time intervals, see
Optimize hypertable chunk intervals.
By default, indexes are automatically created when you create a hypertable. The default index is on time, descending.
You can prevent index creation by setting the create_default_indexes option to false.
Hypertables have some restrictions on unique constraints and indexes. If you want a unique index on a hypertable, it must include all the partitioning columns for the table. To learn more, see Enforce constraints with unique indexes on hypertables.
You can prevent index creation by setting the create_default_indexes option to false.
Partitioning on time is the most common use case for hypertable, but it may not be enough for your needs. For example, you may need to scan for the latest readings that match a certain condition without locking a critical hypertable.
Note
The use case for a partitioning dimension is a multi-tenant setup. You isolate the tenants using the tenant_id space
partition. However, you must perform extensive testing to ensure this works as expected, and there is a strong risk of
partition explosion.
You add a partitioning dimension at the same time as you create the hypertable, when the table is empty. The good news
is that although you select the number of partitions at creation time, as your data grows you can change the number of
partitions later and improve query performance. Changing the number of partitions only affects chunks created after the
change, not existing chunks. To set the number of partitions for a partitioning dimension, call set_number_partitions.
For example:
Create the hypertable with the 1-day interval chunk interval
CREATE TABLE conditions("time" timestamptz not null,device_id integer,temperature float)WITH(timescaledb.hypertable,timescaledb.partition_column='time',timescaledb.chunk_interval='1 day');Add a hash partition on a non-time column
select * from add_dimension('conditions', by_hash('device_id', 3));Now use your hypertable as usual, but you can also ingest and query efficiently by the
device_idcolumn.Change the number of partitions as you data grows
select set_number_partitions('conditions', 5, 'device_id');
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.